Claude Opus 4.7: Coding Upgrades, Pricing, Context, and the Mythos Backstory

Anthropic shipped Claude Opus 4.7 on April 16, 2026 — less than three months after Opus 4.6. The version bump is small on paper, but the actual gap is not: CursorBench jumps from 58% on 4.6 to 70% on 4.7, Rakuten SWE-Bench solves 3× more tasks, and visual acuity climbs from 54.5% all the way to 98.5%. Pricing stays flat, with the 1M-context premium still removed.
This post walks through what actually changed — version diff, benchmark numbers, new features, breaking changes, pricing, and context limits — the angles developers usually care about first. It also digs into something unusual: Anthropic openly stating that Opus 4.7 is weaker than its internal sibling, Mythos Preview. Why that is, and what it means for the rest of us, is worth understanding.
What Claude Opus 4.7 is
Claude Opus sits at the top of Anthropic’s three-tier lineup (Haiku, Sonnet, Opus). It’s the model you reach for when the task demands deep reasoning, long-running workflows, or autonomous agent operation — and accept the higher inference cost and latency in return. Sonnet handles most everyday work. Haiku is for cost- and latency-sensitive loops. Opus is the “spare no expense, get the strongest result” option.
Opus 4.7’s headline focus is software engineering and agent capability. Anthropic’s announcement positions it as a meaningful step up over 4.6 on three fronts: writing code, operating as an agent, and sustaining focus across long tasks. Beyond pure language work, vision and image handling got a major upgrade too — Claude Code users will feel this one in particular.
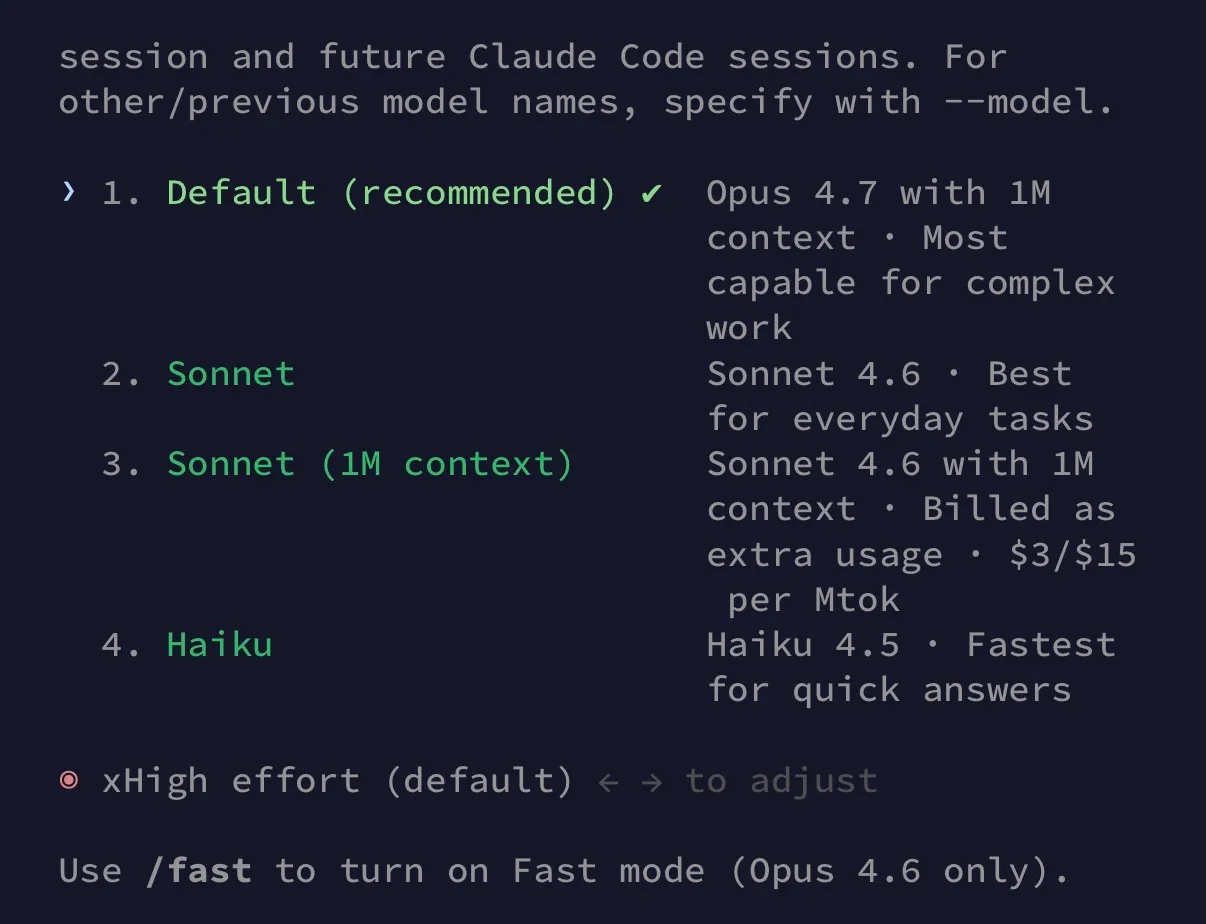
The model ID is claude-opus-4-7. It’s live on the Anthropic API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry, and available to Pro, Max, Team, and Enterprise subscribers on claude.ai. Anthropic also announced that starting April 23, 2026, the default model for Enterprise pay-as-you-go and API requests will switch from 4.6 to 4.7 — any request that doesn’t pin a specific model version will silently run on the new one.
Diff at a glance: Opus 4.7 vs 4.6
Here’s the table most developers will want first:
| Item | Opus 4.6 | Opus 4.7 |
|---|---|---|
| Model ID | claude-opus-4-6 | claude-opus-4-7 |
| Input price | $5 / 1M tokens | $5 / 1M tokens |
| Output price | $25 / 1M tokens | $25 / 1M tokens |
| Context window | 1M tokens | 1M tokens |
| Long-context premium | None (removed 2026-03) | None; same per-token rate at 9K and 900K |
| Max output | 64K tokens | 128K tokens |
| Effort levels | low / medium / high / max | adds xhigh, between high and max |
| Task budgets | — | New beta; model self-allocates |
| Extended thinking budget | Manual specification | Removed; only adaptive thinking remains |
| Max image resolution | 1568px / 1.15 MP | 2576px / 3.75 MP |
| Tokenizer | Previous version | New tokenizer; up to 35% more tokens per same input |
| Prompt caching | Supported, 90% off | Supported, 90% off |
| Batch processing | Supported, 50% off | Supported, 50% off |
Note: Per-token prices are identical between 4.6 and 4.7, but that doesn’t mean “the same job costs the same on 4.7.” Opus 4.7 ships with a new tokenizer that can use up to 35% more tokens for the same input, so your actual bill may tick up — the sticker price didn’t move, but the token count did. Details in the “New tokenizer” section below.
A few of these items deserve their own look.
Coding and agent capability
Coding is the headline of this release. Anthropic and third-party partners published these numbers:
| Benchmark | Opus 4.6 | Opus 4.7 | Change |
|---|---|---|---|
| CursorBench | 58% | 70% | +12 points |
| Rakuten SWE-Bench (tasks solved) | 1× | 3× | 3× |
| Internal 93-task coding benchmark | — | — | +13% |
| Visual-acuity benchmark | 54.5% | 98.5% | +44 points |
| Terminal-Bench | Some failures | Previously failing tasks now solvable | — |
Rakuten’s SWE-Bench numbers are the most interesting: not only does 4.7 solve 3× more tasks than 4.6, but both code quality and test quality improved in the double digits. For long-running coding agents, that means a wider range of solvable work and more consistent output quality.
The vision jump is probably the most dramatic single number — 54.5% to 98.5%. Anthropic also raised per-image resolution from 1568px / 1.15 MP to 2576px / 3.75 MP, and the model’s coordinate outputs now map 1:1 with actual pixels. For GUI agents, browser automation, and design-review workflows that lean heavily on vision, 4.7 is where the gap will be most obvious.
Note: Anthropic did not publish exact SWE-bench Verified or GPQA Diamond numbers in the model card this time. The figures circulating are mostly third-party estimates, so we’re not listing them here to avoid misleading anyone.
What’s new in Opus 4.7
New xhigh effort level
Anthropic’s effort levels used to be just low, medium, high, and max. Opus 4.7 adds xhigh in between high and max. The reasoning is straightforward: the token-cost gap between high and max was too big, and xhigh gives developers a “want more depth, but not the full max tax” middle option.
Claude Code defaulted to medium effort on Opus 4.6, but on Opus 4.7 the default is xhigh — so expect higher token usage out of the box, and adjust down if you need to.
Task budgets (beta)
Task budgets is a new beta feature, gated behind the task-budgets-2026-03-13 header on the Messages API. It’s conceptually different from max_tokens: instead of a hard ceiling, the model is told how much token budget remains and decides on its own how to split that across thinking versus output. It’s self-allocation.
In practice, task budgets fits long-running agent work — something like “finish multi-turn retrieval, code editing, and test runs within this budget.” For one-off API calls, keep using max_tokens; there’s no need to flip the beta header just for the upgrade.
Higher-resolution images
The image cap went from 1568px / 1.15 MP up to 2576px / 3.75 MP. That means larger, more detailed images go in directly — screenshots, design mockups, scanned PDF pages where tiny text matters. You can skip the pre-tiling or downsizing step you used to need.
New tokenizer
Opus 4.7 ships with a new tokenizer. The same input text can use up to 35% more tokens on 4.7 (Anthropic’s framing is “1× to 1.35×,” depending on content). Two practical implications: first, any token-based cost model needs to be re-baselined; second, prompt caches do not transfer across 4.6 and 4.7. If your workflow depends on exact token counts (custom chunking, quota allocation), test end-to-end before flipping the model ID.
Side note: a tokenizer change usually signals a fresh training run — embedding matrices are tied to the vocabulary, so old weights can’t be reused as-is. From that angle, 4.6 to 4.7 is much closer to “a new model in the same training generation” than “a small 4.6 tune-up,” even if the version bump is only 0.1. The SWE-bench Pro jump from 53.4% to 64.3% and the 54.5% → 98.5% visual result are consistent with that read.
Counter-intuitively, most industry tokenizer upgrades pitch “better compression, fewer tokens for the same content” as the win — Opus 4.7 goes the other way. Anthropic only says the new tokenizer “contributes to model performance across a range of tasks,” without spelling out the design tradeoffs. Plausible directions include: expanded multilingual or code vocabulary, splitting confusable merged tokens, tokenizer boundaries prioritizing semantics over compression — but these are all speculation. The observable trade is “35% more tokens” for “benchmark jumps like these,” and for now the math looks favorable.
Breaking changes when upgrading
4.7 is not a pure compatibility bump. A few API behavior changes deserve attention:
- Extended thinking budget removed: 4.6 let you manually set
thinking.budget_tokens. 4.7 only supports adaptive thinking (the model decides whether and how deep to think), and it’s off by default. - Sampling parameters restricted: Setting
temperature,top_p, ortop_kto a non-default value now returns HTTP 400. Anthropic’s stance is: stop tuning randomness via these knobs, use effort levels and prompt design instead. - Thinking content no longer returned by default: To see the model’s reasoning content, you have to opt in with
display: "summarized". It’s no longer embedded in the response automatically. - More literal behavior: Anthropic says 4.7 follows prompt instructions more strictly, tailors response length more tightly to the task, fires fewer default tool calls and subagents, and has a more direct tone with fewer emojis.
Before flipping the model ID, the safer move is to review your prompts and sampling settings. If any downstream code parses thinking content, switch to explicit opt-in — otherwise you’ll get empty strings.
Pricing and context limits
Opus 4.7’s pricing matches 4.6 exactly: $5 / $25 per 1M tokens (input / output). Flat pricing on a new flagship is unusual — version bumps typically come with a price hike. Anthropic held the line, which means your existing cost model doesn’t need a rewrite.
Also worth calling out: there’s no long-context premium. When Opus 4.6 first shipped, requests above 200K tokens were priced at a surcharge. Anthropic removed that premium on March 16, 2026, and both 4.6 and Sonnet 4.6 moved to a flat rate across the full context. Opus 4.7 inherits this pricing: 9K and 900K requests cost the same per token. If your workflow regularly feeds full codebases, long PDFs, or large conversation histories, this is a real-dollar win.
The cost-saving tools are intact:
- Prompt caching: 90% off on cache hits
- Batch processing: 50% off for non-real-time batch workloads
- Max output doubled: 64K → 128K, so outputs that used to require chunking fit in one call
Note: the new tokenizer can add up to 35% more tokens for the same content, so the real bill on 4.7 may be slightly higher even at flat pricing. For cost-sensitive workloads, run a small real-traffic A/B before flipping the model ID.
Changes on the Claude Code side
Claude Code also shipped alongside the model. The most visible new command is /ultrareview — a focused code-review session that runs a stricter multi-stage flow than asking “review this PR” in a normal conversation. It categorizes issues, prioritizes them, and specifically avoids editing the code (preventing review from drifting into implementation).
Beyond the new command, Opus 4.7’s default behavior inside Claude Code has shifted: fewer tool calls, fewer subagent triggers, a more direct tone, and essentially no emojis in responses. This tracks with the “more literal prompt-following” theme from earlier — overall, it feels more like collaborating with an experienced engineer who doesn’t say much.
What Mythos Preview is
Talking about Opus 4.7 means you have to talk about Claude Mythos Preview — a model stronger than 4.7 that Anthropic chose not to ship publicly.
Mythos first surfaced on March 26, 2026, when an Anthropic CMS misconfiguration let a draft article get indexed by search engines. Fortune broke the story first. Anthropic formally confirmed Mythos Preview’s existence on April 7, acknowledging it as a new-generation general-purpose model (internal codename: Capybara) that, in internal testing, could autonomously discover and exploit zero-day vulnerabilities across mainstream operating systems and browsers.
Because a model at that capability level could be abused for real-world attacks if released broadly, Anthropic chose to run Project Glasswing instead: Mythos Preview is restricted to 12 strategic partners — Amazon, Apple, Microsoft, Cisco, CrowdStrike, Linux Foundation, Palo Alto Networks, and others — for defensive security research. The goal is to let these teams catalog vulnerabilities before attackers reach the same capability level. Regular developers and Pro/Max subscribers do not have access.
How Opus 4.7 relates to Mythos Preview
A common framing online is that “Opus 4.7 is a scaled-down Mythos.” That framing has official backing — Anthropic wrote this directly in the Opus 4.7 announcement:
Although it is less broadly capable than our most powerful model, Claude Mythos Preview, it shows better results than Opus 4.6 across a range of benchmarks.
Opus 4.7’s cyber capabilities are not as advanced as those of Mythos Preview — indeed, during its training we experimented with efforts to differentially reduce these capabilities.
In plain terms: Opus 4.7 is less broadly capable than Mythos Preview, and Anthropic deliberately experimented with selectively reducing its cyber-attack capabilities during 4.7’s training. So “scaled-down version” is accurate specifically on the point of “offensive security capability was intentionally held back.”
Strictly speaking, though, 4.7 wasn’t produced by trimming Mythos Preview after the fact. A more precise description: the two are parallel outputs of the same training generation. Mythos represents Anthropic’s current capability ceiling; Opus 4.7 is the public release with security-relevant capabilities selectively reduced. Mythos stays inside Project Glasswing for defensive work; Opus 4.7 goes out to general developers.
The reasoning behind the split is practical: ship the safer 4.7 into real production first, watch for surprises at scale, sharpen the safeguards and monitoring, and only then consider opening up Mythos-class capabilities more broadly. From that angle, Opus 4.7 is a stepping stone to eventually releasing Mythos-class capability — which is also why Anthropic is willing to openly say “we have something stronger, and we’re not shipping it yet.”
How to start using it
Upgrading to 4.7 depends on how you access Claude:
- Claude Pro / Max / Team / Enterprise subscribers: Pick Opus 4.7 from the model dropdown on claude.ai. No extra setup.
- Anthropic API: Set the
modelfield toclaude-opus-4-7on Messages API.claude-opus-4-6remains available; there’s no forced deprecation yet. - Claude Code: Upgrade to the latest version and pick Opus 4.7 in model settings. Claude Code also supports 1M context — sessions above 200K tokens auto-enable it, no toggle needed.
- Bedrock / Vertex AI / Microsoft Foundry: Grab the model ID from each platform’s console. Behavior matches direct API calls.
Also: starting April 23, 2026, the default model for Enterprise pay-as-you-go and API will flip from 4.6 to 4.7. If you have a production workflow that depends on 4.6-specific behavior (prompts tuned for 4.6, old thinking-budget mechanics), pin the model field explicitly to claude-opus-4-6 to avoid the silent switch.
FAQ
A few questions that have come up repeatedly since the 4.7 release:
When does upgrading to 4.7 make sense?
When a new model ships, “should we upgrade everything” is a fair question. These are situations where 4.7 clearly pays off:
- Long-running coding agent workflows (the 3× solve-rate benefit lands here most directly)
- Browser automation, GUI agents, anything that needs to read small detail in screenshots
- Long-context work that used to hit the premium cost cliff (full codebases, long PDFs, heavy conversation history)
- Code review, complex refactors, engineering tasks that need careful reasoning
When should you stick with 4.6 or a different model?
Conversely, these cases are better served by something else:
- Plain-text conversation, customer support, summarization — Sonnet handles these at a fraction of the cost
- Latency-sensitive chatbots — Haiku is faster and cheaper
- Workflows already heavily tuned on 4.6’s thinking budget or custom sampling — moving to 4.7 means re-tuning; if there’s no urgency, wait it out
- SaaS billing models with tight token-cost accounting — the new tokenizer will shift usage math, so pricing logic needs a re-baseline first
Another way to put it: Opus 4.7’s value concentrates in “complex coding + long context + vision.” If your actual workload is well within Sonnet or Haiku range, pushing to Opus 4.7 isn’t economically worth it.
Will the actual bill be higher on 4.7 than 4.6?
Per-token pricing is identical ($5 / $25 per 1M tokens). But the same content can use up to 35% more tokens on 4.7 due to the new tokenizer — so “the same job” will typically cost a little more, not because of a price hike but because the token count grew. Long-context work does genuinely get cheaper: both late-4.6 and 4.7 have no long-context premium, so 9K and 900K requests cost the same per token.
For cost-sensitive workflows, A/B with a small slice of real traffic before committing. That’ll tell you whether your content lands closer to 1.0× or 1.35×.
Can regular developers access Mythos Preview?
Not currently. Mythos Preview is only distributed through Project Glasswing to 12 strategic partners Anthropic selected (Amazon, Apple, Microsoft, Cisco, CrowdStrike, Linux Foundation, Palo Alto Networks, etc.), for defensive security research. Pro / Max / Team / Enterprise subscribers, API users, and third-party platforms like Bedrock and Vertex AI don’t have access. There’s no waitlist, no beta application.
For general use, Opus 4.7 is the strongest publicly-available version right now. Wider access to Mythos-class capability depends on how the safeguards mature.
What are the easiest gotchas to hit on upgrade day?
Four API-side changes most likely to break code on day one:
- Requests still sending
thinking.budget_tokensnow return HTTP 400 — switch tothinking: {type: "adaptive"} - Requests still sending non-default
temperature,top_p, ortop_kalso return 400 — strip these fields from the request - Any downstream code relying on thinking content will get empty strings, since 4.7 no longer returns thinking by default — opt in with
display: "summarized" - Workflows that were already brushing up against
max_tokensmay hit truncation because of the tokenizer change — add some headroom tomax_tokens, and re-measure any compaction triggers
How do extended thinking budget and effort level differ?
They control completely different things.
Extended thinking budget (4.6 syntax: thinking.budget_tokens: N) is a precise hard ceiling — it only governs the maximum tokens spent on the thinking phase, and setting it forces thinking on.
Effort level (output_config.effort) is a coarse-grained knob across five steps: low / medium / high / xhigh / max. It doesn’t just affect thinking depth — it also influences tool call frequency, subagent triggering, and response length, all at once. A rough analogy: budget is a manual throttle, effort is an autopilot mode.
Anthropic’s official reason for dropping budget in 4.7 is “adaptive thinking performs more consistently than fixed budget in internal evaluations.” The broader design shift is pulling internal controls back into the model itself — the same release also removed the temperature / top_p / top_k knobs in the same direction. For developers, that means losing precise token-budget prediction; the replacement is task_budget (a soft suggestion) to control the token ceiling across the full loop.
Migration in practice:
# 4.6 version
response = client.messages.create(
model="claude-opus-4-6",
thinking={"type": "enabled", "budget_tokens": 32000},
max_tokens=8000,
)
# 4.7 equivalent
response = client.messages.create(
model="claude-opus-4-7",
thinking={"type": "adaptive"}, # explicit opt-in
output_config={"effort": "high"}, # effort replaces budget
max_tokens=10000, # headroom for new tokenizer
)The real trap: code that used {type: "enabled", budget_tokens: N} on 4.6 to force thinking will return HTTP 400 on 4.7 — 4.7 no longer accepts enabled. Switch to {type: "adaptive"} and use effort to control depth. For 4.6 code that didn’t use the thinking field at all (omitted = disabled), 4.7 behaves identically.
Note: This whole breaking change only affects developers hitting the Anthropic Messages API directly (or through Bedrock / Vertex / Foundry). Claude Code, Claude Managed Agents, and the claude.ai web / mobile apps don’t need any changes — the harness handles thinking settings on these surfaces. Claude Code has defaulted to adaptive thinking + medium effort since 2026-02, and on 4.7 even the CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING env var stops taking effect — adaptive is always on.
How do I pick between xhigh and max effort?
Anthropic’s guidance: for coding and agent tasks, start at xhigh. For high-quality work with cost under control, start at high. Go to max only when you need absolute best-case results. xhigh fills the cost cliff between high and max — jumping from high straight to max was overkill for a lot of scenarios, and xhigh gives a finer choice.
In practice, max is the “spare no expense for the best result” setting. Token consumption is noticeably higher than xhigh, so everyday workloads don’t need to live on max.
Is 4.7 more likely to refuse requests?
On security-related topics, yes. Anthropic mentions “real-time cybersecurity safeguards” in 4.7, meaning requests around attack techniques or vulnerability exploitation are refused more readily than on 4.6. For legitimate security research, red-team testing, or CTF practice, you can apply to the Cyber Verification Program to get appropriate access.
For non-security everyday tasks, there’s no added refusal layer — the experience is about the same as 4.6. Separately, 4.7’s overall tone is more direct and literal than 4.6. Prompt tricks like “please don’t over-interpret my instructions” that helped on older models should actually be removed on 4.7 — otherwise the model will follow them too strictly.
Wrap-up
The Opus 4.7 release isn’t about jumping to a new generation number — it’s about pushing coding, vision, and long-context on the same price point, while making a few breaking API changes worth preparing for in advance. For software engineering workflows, it’s a version worth actually trying. For everyday tasks, Sonnet and Haiku remain the more sensible picks.
The Mythos Preview + Project Glasswing arrangement hints at a new way Anthropic thinks about releasing frontier models — not “train it, ship it” but “ship the safer version first, validate safeguards in real deployment, then consider opening up.” That cadence means users see top-tier capability later than they used to, but it keeps overall AI deployment risk in a more predictable range.
References
- Anthropic – Introducing Claude Opus 4.7
- Anthropic – Claude Opus product page
- Anthropic – Models overview
- Anthropic – Pricing
- Anthropic Red – Claude Mythos Preview
- Axios – Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos
- Fortune – Anthropic ‘Mythos’ AI model representing ‘step change’