Claude Opus 4.7 完全解説|コーディング・価格・コンテキストと Mythos の舞台裏

Anthropic は 2026 年 4 月 16 日、Claude Opus 4.7 を正式にリリースしました。前世代の Opus 4.6 から 3 ヶ月経たないうちの登場です。バージョン番号の上がり幅は小さいですが、実際の差は決して小さくありません。公式発表によると CursorBench は 4.6 の 58% から 70% へ、Rakuten SWE-Bench の解決数は 4.6 の 3 倍、ビジュアル認識の精度は 54.5% から 98.5% まで一気に上がりました。価格は 4.6 と同じで、1M コンテキストも追加料金なしのままです。
本記事では、バージョン差分、ベンチマーク、新機能、破壊的変更、価格とコンテキスト制限といった、開発者が最も気になる角度から Opus 4.7 全体を整理します。最後に、Anthropic が珍しく「Opus 4.7 は同門の Mythos Preview より弱い」と明言した件 —— その背景と開発者にとっての意味 —— も合わせて見ていきます。
Claude Opus 4.7 とは
Claude Opus は Anthropic の 3 層プロダクトライン(Haiku、Sonnet、Opus)の最上位に位置するモデルで、最も複雑な推論、長時間ワークフロー、エージェントの自律操作といった場面を想定しています。その分、推論コストとレイテンシも最も高くなります。Sonnet は日常のほとんどのタスクに適しており、Haiku はコストとレイテンシにシビアな場面向け、Opus は「コストを気にせず最強の性能を取りにいく」時に選ぶ選択肢です。
Opus 4.7 が主に強化したのはソフトウェアエンジニアリングとエージェント能力です。Anthropic 公式の発表では「コーディング、エージェント操作、長時間タスクの維持」という 3 点で Opus 4.6 より明確に進歩したと位置づけています。純粋な言語能力に加えて、ビジョン理解や画像処理も大きく向上しており、特に Claude Code ユーザーは体感しやすい変化になるはずです。
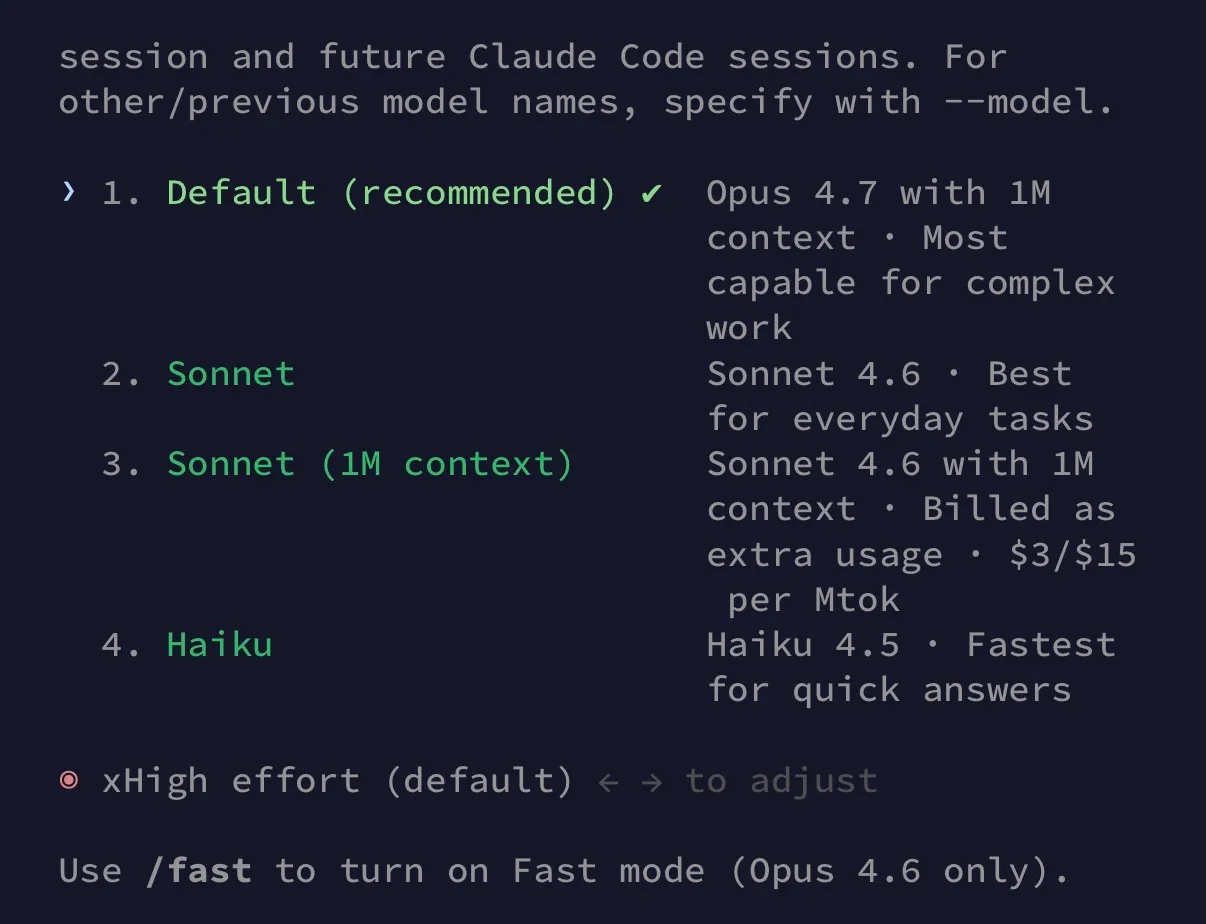
モデル ID は claude-opus-4-7 で、Anthropic API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry に提供されており、Claude の Pro・Max・Team・Enterprise プランでも同時に利用できます。Anthropic の発表では、2026 年 4 月 23 日から Enterprise の従量課金と API のデフォルトモデルが 4.6 から 4.7 へ切り替わるとも明言されています。モデルバージョンを明示しないリクエストは、自動的に新モデルで動くことになります。
Opus 4.6 との差分
まずは開発者が最も気にしそうな項目を、1 枚の表にまとめます。
| 項目 | Opus 4.6 | Opus 4.7 |
|---|---|---|
| モデル ID | claude-opus-4-6 | claude-opus-4-7 |
| Input 価格 | $5 / 1M tokens | $5 / 1M tokens |
| Output 価格 | $25 / 1M tokens | $25 / 1M tokens |
| Context window | 1M tokens | 1M tokens |
| 長 context 追加料金 | なし(2026-03 に撤廃済み) | なし、900K と 9K は同一トークン単価 |
| Max output | 64K tokens | 128K tokens |
| Effort levels | low / medium / high / max | xhigh を追加、high と max の間 |
| Task budgets | なし | 新規 beta、モデルが自己配分 |
| Extended thinking budget | 手動指定可能 | 削除、adaptive thinking のみ |
| 画像最大解像度 | 1568px / 1.15MP | 2576px / 3.75MP |
| Tokenizer | 旧版 | 新版、同じ内容で最大 35% 多い tokens |
| Prompt caching | 対応、90% オフ | 対応、90% オフ |
| Batch processing | 対応、50% オフ | 対応、50% オフ |
注意: 表の上では Opus 4.7 と Opus 4.6 の単価(input / output の 1M token あたり)はまったく同じですが、これは「同じ仕事を 4.7 に移すと料金が同じ」という意味ではありません。Opus 4.7 は新しい tokenizer に切り替わっており、同じテキストでも最大 35% 多くの tokens を消費するため、実際の請求額は少し上がる可能性があります。単価は上がっていないが、token 数が増えた、という状況です。詳しい理由は後述の「新しい tokenizer」の節で説明します。
tokenizer 以外にも、もう少し踏み込んで説明しておきたいポイントがいくつかあるので、順に見ていきます。
コーディングとエージェント能力の向上
今回の Opus 4.7 で最も強調されているのはコーディング能力です。Anthropic と第三者パートナーが公開している数字は以下のとおりです。
| Benchmark | Opus 4.6 | Opus 4.7 | 変化 |
|---|---|---|---|
| CursorBench | 58% | 70% | +12 ポイント |
| Rakuten SWE-Bench(解決数) | 1× | 3× | 3 倍 |
| 内部 93-task coding benchmark | — | — | +13% |
| Visual-acuity benchmark | 54.5% | 98.5% | +44 ポイント |
| Terminal-Bench | 一部失敗 | 以前失敗したタスクも解ける | — |
Rakuten が公開した SWE-Bench の数字は特に興味深く、解決数は 4.6 の 3 倍で、しかも code quality と test quality の両面でも二桁パーセントの改善を示しています。長時間のコーディングエージェントワークフローにとっては、解ける範囲が広がり、出力の品質もより安定する、という意味になります。
ビジョン認識の部分はおそらく今回最もドラマチックな数字です —— 54.5% から 98.5% まで一気に跳ね上がりました。Anthropic は同時に 1 枚あたりの画像解像度を 1568px / 1.15MP から 2576px / 3.75MP へ引き上げ、モデルが出力する座標は実際のピクセルと 1:1 で対応するようになりました。GUI エージェント、ブラウザ操作、デザインレビューといったビジョン依存のワークフローでは、4.7 が最も体感差の出る領域になるはずです。
注意: SWE-bench Verified や GPQA Diamond の公式スコアは、今回 Anthropic の model card には完全には記載されませんでした。出回っている数字の多くは第三者推定のため、誤解を避ける意味でここでは列挙しません。
Opus 4.7 の新機能
新しい xhigh effort level
これまで Anthropic の effort level は low、medium、high、max の 4 段階でした。今回は high と max の間に xhigh が追加されています。設計上の狙いは明快で、high と max の間の token コスト差が大きすぎたため、「max ほどではないがもう少し深く考えてほしい」という中間の選択肢を提供するものです。
Claude Code は Opus 4.6 のときデフォルトが medium effort でしたが、Opus 4.7 ではデフォルトが xhigh に変わっています。そのため初期状態でも token 消費量は増えますので、必要に応じて下げて使うのがおすすめです。
Task budgets(beta)
Task budgets は今回追加された beta 機能で、Messages API に task-budgets-2026-03-13 header を付けたときに有効になります。これまでの max_tokens のような硬い上限の考え方とは異なり、モデルに「あと何 token 分の予算が残っているか」を伝え、それを思考と出力のどこに使うかはモデル自身に委ねる、という自己配分の仕組みです。
実際の用途としては、長時間エージェントタスク(予算内で検索、コード編集、テスト実行などを多段で回すような場面)に向いています。単発の API 呼び出しは従来どおり max_tokens で十分で、新機能のためだけに beta header を付ける必要はありません。
高解像度画像
画像の上限が 1568px / 1.15MP から 2576px / 3.75MP まで引き上げられました。より大きく、より細部のある画像をそのまま投入できるようになります。スクリーンショット、デザイン稿、PDF のスキャンページなど、小さい文字まで読み取ってほしい場面では、事前に分割や縮小をする手間が省けます。
新しい tokenizer
Opus 4.7 は新しい tokenizer に切り替わっており、同じテキストが 4.7 上で消費する token 数は最大 35% 増える可能性があります(公式の言い方は「1× から 1.35×、内容による」)。実務的な意味は 2 つです。まず、token 単位のコスト試算を引き直す必要があります。次に、既存の prompt cache は 4.6 と 4.7 の間で共有されません。token 数に厳密に依存するワークフロー(自前のチャンク分割、クォータ配分など)は、切り替え前にひととおり実測しておくと安心です。
余談として、tokenizer が変わるということは通常モデルが再訓練されていることを示唆します —— embedding 行列と語彙表は結び付いているため、旧い重みをそのまま流用することはできません。そう考えると、4.6 から 4.7 はバージョン番号こそ 0.1 ですが、「4.6 を微調整したアップデート」というより「同じ訓練世代の新しいモデル」に近い存在だと見るのが妥当です。SWE-bench Pro が 53.4% から 64.3%、ビジョンが 54.5% から 98.5% というジャンプ幅も、この見方と整合します。
もう 1 点、業界で tokenizer を切り替える際は通常「圧縮率が上がり、同じ内容をより少ない token で表現できる」ことをセールスポイントにするのが一般的ですが、Opus 4.7 は逆です —— 同じ内容でむしろ多くの token を消費します。Anthropic 公式は「新しい tokenizer は多様なタスクでのモデル性能向上に貢献する」としか述べておらず、具体的な設計理由までは明かしていません。考えられる方向としては、多言語・コード関連の語彙拡張、紛らわしい合成 token の分割、圧縮率より意味境界を優先したトークン化、などが挙げられますが、すべて推測の域を出ません。結果だけ見れば、Anthropic は「35% 多い token コスト」と引き換えに「ベンチマークの大幅な向上」を取った格好で、この取引は今のところ割に合っているように見えます。
アップグレード時の破壊的変更
4.7 は純粋な互換アップデートではありません。API の挙動で、いくつか注意したい変更があります。
- Extended thinking budget が削除:4.6 では
thinking.budget_tokensを手動指定できましたが、4.7 では adaptive thinking のみ(思考するかどうか、どこまで深く考えるかをモデル自身が判断)となり、デフォルトはオフです。 - Sampling パラメータの制限:
temperature、top_p、top_kをデフォルト以外の値に設定すると HTTP 400 が返るようになりました。Anthropic の設計思想は「これらのパラメータで randomness を調整するのをやめ、effort level と prompt で誘導してほしい」というものです。 - Thinking content がデフォルトで返されない:モデルの思考内容を見るには
display: "summarized"を明示的に opt-in する必要があります。4.6 のようにレスポンスに自動で含まれることはなくなりました。 - 動作がより文字通りに:Anthropic によれば、4.7 は prompt の指示をより厳密に文字通り実行し、回答の長さもタスクに必要な分量に合わせ、デフォルトの tool call や subagent の発火回数が減り、全体のトーンもより直接的で emoji が少なくなります。
4.7 に切り替える前に、prompt と sampling 設定を一度レビューしておくのが安全です。thinking content を下流処理で利用していたコードは、明示的な opt-in に書き換える必要があります。そうしないと空欄を受け取ることになります。
価格とコンテキスト制限
Opus 4.7 の価格は Opus 4.6 と完全に同じで、input $5 / output $25(1M tokens あたり)です。新しいフラッグシップの発表で据え置き価格というのは珍しく、通常はバージョンが上がれば価格も上がるのが普通ですが、今回 Anthropic はそのまま据え置きでアップグレードしたため、既存のコストモデルを再構築する必要はありません。
もう 1 点押さえておきたいのは、長 context に追加料金がかからないことです。Opus 4.6 がリリースされた当初は、いわゆる long-context premium があり、200K token を超えるリクエストには割増料金がかかっていました。しかし Anthropic は 2026 年 3 月 16 日にこの premium を撤廃しており、Opus 4.6 と Sonnet 4.6 の双方で、全 context に対して統一料金になっています。Opus 4.7 もこの料金体系を継承しており、9K token を送っても 900K token を送っても、1 token あたりの単価は同じです。コードベース全体や長い PDF、大量の対話履歴を丸ごと投入するような用途では、実コストに大きな違いが出るポイントです。
コスト削減のためのツールは引き続き完備されています。
- Prompt caching:キャッシュヒットした部分は 90% オフ
- Batch processing:非リアルタイムのバッチタスクは 50% オフ
- Max output が倍増:64K から 128K へ、これまで分割して呼び出していた長い出力を 1 回で取り切れる
注意: 新しい tokenizer は同じ内容でも最大 35% 多い token を消費するため、4.7 に切り替えると同じ価格帯でも実際の請求額は少し上がる可能性があります。コストにシビアなワークフローでは、切り替え前に小量の実トラフィックで実測することをおすすめします。
Claude Code 側の変更
Claude Code も同時にアップデートされています。最も目立つ新コマンドは /ultrareview で、code review に特化したセッションを開くためのものです。通常の会話で「この PR を review してほしい」と頼むのと違い、ultrareview はより厳格な多段プロセスで問題を分類・優先順位付けし、コードを勝手に書き換えることはしません(review が実装に流れてしまうのを防ぐ設計です)。
新コマンドに加えて、Claude Code 内での 4.7 のデフォルト動作も変わっています:tool call や subagent の発火が 4.6 より控えめ、トーンがより直接的、回答に emoji をあまり入れなくなりました。先ほど触れた「指示がより文字通りに解釈される」設計と一貫した方向性で、全体としては「経験豊富だが寡黙なエンジニアと組んでいる」ような感触に近づいています。
Mythos Preview とは
Opus 4.7 の話をするなら、Claude Mythos Preview も避けては通れません —— 4.7 より強力だが、Anthropic が公開リリースしないと決めたモデルです。
Mythos は 2026 年 3 月 26 日、Anthropic 自身の CMS 設定ミスで下書き記事が検索エンジンに index され、意図せず表に出てしまったのが最初の露出でした。Fortune が独自スクープとして最初に報じています。その後 Anthropic は 4 月 7 日に Mythos Preview の存在を正式に公表し、内部コードネーム Capybara と呼ばれる新世代の汎用モデルで、内部評価において主要な OS とブラウザを対象に、自律的にゼロデイ脆弱性を発見・悪用できる能力を持つことを認めました。
この能力水準のモデルをそのまま公開リリースすると、実際の攻撃に悪用されるリスクが高すぎるため、Anthropic はコードネーム Project Glasswing の計画を選択しました。Mythos Preview は Amazon、Apple、Microsoft、Cisco、CrowdStrike、Linux Foundation、Palo Alto Networks など 12 社の戦略パートナーに限定して提供し、防御的なセキュリティ研究に使ってもらう、という枠組みです。攻撃者が同等のツールを手にする前に、これらの企業が脆弱性を洗い出せるようにすることが目的です。一般開発者や Pro / Max 加入者は Mythos を入手できません。
Opus 4.7 と Mythos Preview の関係
ネット上でよく聞く言い方に「Opus 4.7 は Mythos Preview の制限版だ」というものがあります。これには実は公式の裏付けがあり、Anthropic が Opus 4.7 の発表にそのまま書いています。
Although it is less broadly capable than our most powerful model, Claude Mythos Preview, it shows better results than Opus 4.6 across a range of benchmarks.
Opus 4.7’s cyber capabilities are not as advanced as those of Mythos Preview — indeed, during its training we experimented with efforts to differentially reduce these capabilities.
噛み砕くと、Opus 4.7 は全体の能力で Mythos Preview より劣り、かつ Anthropic は 4.7 の訓練段階でサイバー攻撃能力を選択的に低下させる実験を意図的に行ったということです。ですので「制限版」という表現は、「攻撃能力が意図的に抑制されている」という一点に関しては完全に正しい記述です。
ただし厳密には、Opus 4.7 が Mythos Preview をあとから刈り込んで作ったわけではありません。より正確な表現は「両者は同一の訓練世代で並行して生まれた別モデル」です。Mythos は Anthropic の現時点の能力上限を代表し、Opus 4.7 はセキュリティ関連能力を意図的に抑えたうえで公開されたバージョン、という位置づけです。Mythos は Project Glasswing のパートナーによる防御研究に、Opus 4.7 は一般開発者向けに提供されます。
このような設計にした狙いも実務的です。まずより安全な 4.7 を実際の本番環境に出し、大規模デプロイで想定外のリスクが顕在化しないかを観察しつつ、safeguards や監視機構を磨き上げる。そこまでやってから、Mythos クラスの能力を安全に対外公開する可能性を検討する、という段階論です。別の見方をすれば、Opus 4.7 は Mythos 級モデルの公開に向けた中間ステップであり、Anthropic が「もっと強いバージョンはあるが、今は公開しない」と自ら明言したのもこの文脈に沿った話です。
使い始めるには
4.7 へのアップグレード方法は、利用形態によっていくつかに分かれます。
- Claude Pro / Max / Team / Enterprise 加入者:claude.ai のモデル選択メニューから Opus 4.7 を選ぶだけで、追加設定は不要です。
- Anthropic API:Messages API の
modelフィールドでclaude-opus-4-7を指定します。旧版のclaude-opus-4-6も引き続き利用可能で、強制的な廃止はされていません。 - Claude Code:最新バージョンにアップデートしたうえで、model 設定で Opus 4.7 に切り替えます。Claude Code は 1M context にも対応しており、200K を超えるセッションでは自動で有効になるため、個別の切り替えは不要です。
- Bedrock / Vertex AI / Microsoft Foundry:対応するモデル ID は各プラットフォームの console から取得します。挙動は直接 Anthropic API を叩く場合と同じです。
もう 1 点、2026 年 4 月 23 日から Enterprise の従量課金と API のデフォルトモデルが 4.6 から 4.7 に切り替わります。本番環境で 4.6 特有の挙動に依存しているワークフロー(prompt が 4.6 向けにチューニングされている、旧い thinking budget に依存している等)がある場合は、model フィールドで明示的に claude-opus-4-6 を指定し、自動切り替えによる影響を避けてください。
よくある質問
Opus 4.7 のリリース後、比較的よく聞かれる質問をいくつかまとめます。
どんな場面で 4.7 にアップグレードする価値があるか?
新モデルが出たとき、「全面的にアップグレードすべきか」は考える価値のある質問です。以下は 4.7 に切り替えるメリットが明確に出る場面です。
- 長時間のコーディングエージェントワークフロー(解決数 3 倍の恩恵が最も直接的)
- ブラウザ自動化、GUI エージェント、スクリーンショットの細部を読み取る場面
- 長 context が必要だが追加料金を避けたい場面(コードベース全体、長い PDF、大量の対話履歴など)
- Code review、複雑なリファクタリング、細かい推論を要するエンジニアリングタスク
どんな場面では 4.6 や他のモデルを使い続けるべきか?
反対に、以下のような場面では他のモデルのほうが合理的です。
- プレーンテキストの対話、カスタマーサポート、要約などの日常タスク —— Sonnet で十分かつコストがずっと安い
- レイテンシ重視のリアルタイム対話や chatbot —— Haiku のほうが速度もコストも適している
- すでに 4.6 で thinking budget やカスタムの sampling パラメータを深く調整済みのワークフロー —— 4.7 に上げると調整をやり直すことになるため、差し迫った必要がなければしばらく様子見でよい
- token コスト試算が極めてシビアな SaaS の課金モデル —— 新しい tokenizer で使用量が変わるため、先に価格ロジックを再計算する必要がある
言い換えると、Opus 4.7 のアップグレード価値は「複雑なコーディング + 長 context + ビジョン」の領域に集中しています。既存のニーズが Sonnet や Haiku の範囲に収まっているなら、無理に Opus 4.7 に上げるのは割に合いません。
4.7 にアップグレードすると実際の請求は 4.6 より高くなるか?
単価は完全に同じ(input $5、output $25 / 1M tokens)ですが、同じ内容を 4.7 で処理すると最大 35% 多くの token を消費する可能性があります。そのため「同じ仕事」に対する請求額はわずかに上がるのが通常ですが、これは値上げではなく tokenizer が新しくなったことが原因です。長 context の部分は逆にしっかり節約が効きます —— 4.6 の後期と 4.7 はどちらも long-context premium がなく、9K と 900K が同一トークン単価です。
コストにシビアなワークフローでは、切り替え前に小量の実トラフィックで A/B を取り、自分のコンテンツタイプが 1.0× 寄りなのか 1.35× 寄りなのかを数値で確認してから判断するのがおすすめです。
一般開発者は Mythos Preview を使えるか?
現時点では使えません。Mythos Preview は Project Glasswing を経由して Anthropic が選定した 12 社の戦略パートナー(Amazon、Apple、Microsoft、Cisco、CrowdStrike、Linux Foundation、Palo Alto Networks など)にのみ提供されており、用途は防御的なセキュリティ研究です。Pro / Max / Team / Enterprise 加入者、API 利用者、Bedrock / Vertex AI などのサードパーティ経由でも Mythos にはアクセスできず、waitlist や beta 申請の窓口もありません。
一般ユーザーにとって Opus 4.7 は、現時点で入手できる最強の公開バージョンです。Mythos クラスのモデルが広く開放されるかどうかは、safeguards の成熟度次第になります。
アップグレード時に最も踏みやすい落とし穴は?
API 側で、切り替え当日にコードが壊れやすい 4 つの変更を挙げておきます。
thinking.budget_tokensを送り続けているリクエストは HTTP 400 になります ——thinking: {type: "adaptive"}に書き換える必要があります。- デフォルト値以外の
temperature、top_p、top_kを送り続けているリクエストも 400 になります —— これらのフィールドはリクエストから丸ごと外す必要があります。 - thinking content を下流処理で利用していたコードは空文字列を受け取ります(4.7 はデフォルトで thinking を返さないため) ——
display: "summarized"で明示的に opt-in してください。 max_tokensの上限ぎりぎりで動いていたワークフローは、新 tokenizer で token を多く消費する関係で切り詰められる可能性があります ——max_tokensに少し余裕を持たせ、compaction のトリガー点も再測定することをおすすめします。
Extended thinking budget と effort level はどう違う?
両者が制御する対象はまったく別のレイヤーです。
Extended thinking budget(4.6 の書き方は thinking.budget_tokens: N)は、精密で硬い token 上限です。「思考」フェーズで使う最大 token 数だけを制御し、設定すると必ず思考する動作になります。
Effort level(output_config.effort)は low / medium / high / xhigh / max の 5 段階の粗粒度のノブです。制御対象は思考の深さだけでなく、tool call の頻度、subagent の発火回数、回答の長さまで含み、それらをまとめて調整します。ざっくり言えば、budget が手動スロットル、effort が自動運転モードのような関係です。
4.7 で budget が廃止された公式理由は「adaptive thinking のほうが固定 budget より内部評価で安定している」というものです。背後にある設計思想の変化は、モデル内部の挙動制御をモデル自身に戻すという方向性で、同じリリースで temperature などの sampling パラメータが外されたのも同じ方向です。開発者にとっては、精密な token 予測能力を失う代わりに、loop 全体の token 上限は task_budget(ソフトな提案)で制御する形になります。
実際のマイグレーションはこんな形になります。
# 4.6 の書き方
response = client.messages.create(
model="claude-opus-4-6",
thinking={"type": "enabled", "budget_tokens": 32000},
max_tokens=8000,
)
# 4.7 の対応する書き方
response = client.messages.create(
model="claude-opus-4-7",
thinking={"type": "adaptive"}, # 明示的に opt-in
output_config={"effort": "high"}, # effort が budget の代わり
max_tokens=10000, # 新 tokenizer 用に余裕を持たせる
)本当の落とし穴は、4.6 で {type: "enabled", budget_tokens: N} を使って強制的に思考させていたコードです。4.7 に移すとそのまま 400 エラーが返ります —— 4.7 は enabled モードを受け付けなくなったためです。{type: "adaptive"} に変更し、effort で深さを制御するように書き換えます。4.6 時代に thinking フィールドを使っていなかったコード(省略 = disabled)であれば、4.7 でも挙動は同じで、対応は不要です。
注意: この破壊的変更が影響するのは、Anthropic Messages API(あるいは Bedrock / Vertex / Foundry)を直接叩く開発者だけです。Claude Code、Claude Managed Agents、claude.ai の Web / モバイルアプリユーザーは何もする必要がありません —— これらの surface は harness 側で thinking 設定を自動的に処理してくれます。Claude Code は 2026-02 から adaptive thinking + medium effort をデフォルトで有効化しており、4.7 では CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING 環境変数も効かなくなり、常に adaptive on となります。
xhigh と max の effort level はどう選び分けるか?
Anthropic 公式の目安としては、コーディングやエージェントのタスクでは xhigh から試す、品質は確保しつつコストも抑えたいタスクでは high を起点、とにかく最強の結果を取りにいくときだけ max、というものです。xhigh は high と max の間のコストの断層を埋める位置付けで、多くの場面で high から一気に max に飛ぶのはオーバーキルだったため、より細かい選択肢を用意した、という位置付けです。
実務上、max は「コストを気にせず最良の結果を取る」レベルです。token 消費は xhigh と比べて目に見えて多くなるため、日常のワークフローで max に常駐させる必要はあまりありません。
4.7 は要求を断りやすくなったか?
セキュリティ関連の話題ではそうです。Anthropic は Opus 4.7 に「real-time cybersecurity safeguards」を追加したと述べており、攻撃技術や脆弱性悪用に関わるリクエストは 4.6 より拒否されやすくなりました。合法的なセキュリティ研究、red team テスト、CTF の練習といった正当な用途であれば、Cyber Verification Program に申請することで対応する権限を取得できます。
セキュリティ以外の日常タスクでは、追加の拒否閾値はなく、4.6 と体感的にほぼ変わりません。余談ですが、4.7 の全体的なトーンは 4.6 より直接的かつ文字通りに解釈するようになっているため、prompt で「指示を過度に解釈しないでください」のような言い回しを入れていた場合、4.7 ではむしろそれを外した方がよい結果になります。そうしないと、モデルがそれも文字通り厳密に実行してしまうためです。
まとめ
今回の Claude Opus 4.7 の更新のポイントは、新しい世代番号に飛んだことではなく、価格据え置きのままコーディング・ビジョン・長 context の 3 本柱をまとめて押し上げたことと、API の挙動面で事前に準備しておきたい破壊的変更をいくつか入れてきたことです。ソフトウェアエンジニアリング関連のワークフローには、実際に試す価値のあるバージョンに仕上がっています。一方で、日常の一般タスクに関しては、Sonnet や Haiku のほうが依然として合理的な選択です。
Mythos Preview と Project Glasswing の組み合わせは、「能力上限に近いモデルをどう公開するか」に対する Anthropic の新しいアプローチを示しています。「訓練できたら公開」ではなく、「先に安全な版を実環境に出し、safeguards を実デプロイで検証してから」という順番です。このリズムの結果、ユーザーが最上位能力のモデルに触れるタイミングは以前より少し遅くなるかもしれませんが、長い目で見れば AI デプロイ全体のリスクをより予測可能な範囲に収めることにつながります。
参考資料
- Anthropic – Introducing Claude Opus 4.7
- Anthropic – Claude Opus product page
- Anthropic – Models overview
- Anthropic – Pricing
- Anthropic Red – Claude Mythos Preview
- Axios – Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos
- Fortune – Anthropic ‘Mythos’ AI model representing ‘step change’